Funciones de Activación
Contents
Funciones de Activación#
Introducción#
Como vimos anteriormente, la red neuronal tiene neuronas que trabajan en consonancia con sus pesos, su sesgo y su respectiva función de activación. En el modo de entrenamiento, se actualizan los pesos y sesgos de las neuronas sobre la base del error en la salida. Este proceso se conoce como retropropagación (backpropagation). Las funciones de activación permiten la retropropagación y los gradientes se suministran junto con el error para actualizar los pesos y sesgos.
La función de activación de un nodo define la salida de ese nodo dada una entrada o un conjunto de entradas. La función de activación decide si una neurona debe activarse o no calculando la suma ponderada y agregando más sesgo con ella.
El propósito de la función de activación es introducir no linealidad en la salida de una neurona.
¿Por qué necesitamos funciones de activación? #
Una red neuronal sin una función de activación es esencialmente un modelo de regresión lineal clásico. La función de activación realiza la transformación no lineal de la entrada, lo que la hace capaz de aprender y realizar tareas más complejas.
Funciones de activación clásicas#
En la entrada, una neurona artificial calcula una «suma ponderada» de su entrada y agrega un sesgo. Como antes, sea \( z = \sum_i x_iw_i + b \), \( z \in \mathcal {R} \). Una vez calculado el valor \( z \), la neurona artificial decide si se debe «disparar» o no, basándose en el valor de \( z \).
Función Step#
Lo primero que nos viene a la mente es ¿qué tal una función de activación basada en umbrales? Si el valor de \( z \) está por encima de cierto valor, declare que se ha activado. Si es menor que el umbral, diga que no.
El umbral más común es 0. La función de activación Step se define como
Observe la figura 1. Obviamente, \(f'(x) = 0\) for \(x\ne 0\).
import numpy as np
import matplotlib.pyplot as plt
x = (-10,0, 10)
y = (0,0,1)
plt.step(x, y , where='pre')
plt.plot(x, y , 'C0o', alpha=0.5)
plt.show()

Figura 1. Función de activación Step.
Activación lineal#
La función de activación lineal está definida por \( f (x) = ax \). Tenga en cuenta que \( f '(x) = a \), para todos \( x \in \mathcal {R} \). Tenga en cuenta que \( - \infty \le f (x) \le \infty \).
La función de activación lineal se utiliza en un solo lugar, es decir, la capa de salida. El efecto de esta función de activación es simplemente escalar los valores provenientes de la última capa oculta, para que se ajusten a los valores objetivo.
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-5,5,100)
y = 2*x
plt.plot(x, y, '-r', label='y=2x')
plt.title('Graph of the linear activation function y=2x')
plt.xlabel('x', color='#1C2833')
plt.ylabel('y', color='#1C2833')
plt.legend(loc='upper left')
plt.grid()
plt.show()
Figure 4. Linear activation function
Funciones de activación tipo sigmoide#
Son funciones cuyo gráfico tiene una forma de «S» alargada. Hay varios tipos de funciones sigmoideas. Las más utilizadas son las funciones logísticas y tangentes hiperbólicas.
Función logística (sigmoid)#
Esta función es definida por
para \(x\in \mathcal{R}\).
Ejercicio#
Verifique que
\(0 \le f(x)\le 1\).
\(f'(x)= f(x)*(1-f(x))\)
Por lo general, \( f (x) \) se usa en la capa de salida de una clasificación binaria, donde el resultado es 0 o 1, ya que el valor de la función sigmoidea se encuentra entre 0 y 1, por lo que el resultado se puede predecir fácilmente como 1 si el valor es mayor. que 0,5 y 0 en caso contrario.
import numpy as np
import matplotlib.pyplot as plt
def logistic(x):
return (1/(1+np.exp(-x)))
x = np.linspace(-5,5,100)
plt.title('Graph of the logistic activation function')
plt.plot(x,logistic(x) )
plt.grid()
plt.show()
Función de activacion Tangente hiperbólica#
La activación que funciona casi siempre mejor que la función sigmoidea es la función tanh también conocida como función tangente hiperbólica . En realidad, es una versión matemáticamente modificada de la función sigmoidea. Ambos son similares y pueden obtenerse una de la otra entre sí.
La función Tanh está definida por
para \(x\in \mathcal{R}\).
Ejercicio#
Verifique que
\(-1 \le f(x)\le 1\).
\(f'(x)= 1 -f(x)^2\).
\(tanh(x) = 2 sigmoid(2x) -1\).
Tanh se usa generalmente en capas ocultas de una red neuronal, ya que sus valores se encuentran entre -1 a 1, por lo que la media de la capa oculta resulta ser 0 o muy cerca de ella, lo que ayuda a centrar los datos al acercar la media a 0. Esto facilita mucho el aprendizaje de la siguiente capa.
import numpy as np
import matplotlib.pyplot as plt
def tanh(x):
return (2/(1+np.exp(-2*x))-1)
x = np.linspace(-5,5,100)
plt.title('Graph of the tanget hyperbolic activation function')
plt.plot(x,tanh(x) )
plt.grid()
plt.show()
Función de activación Unidad de rectificación lineal (ReLu)#
ReLu es la función de activación más utilizada actualmente. Implementada principalmente en capas ocultas de la red neuronal. ReLu se define como
para \(x\in \mathcal{R}\).
Ejercicio#
Verifique que
\(0\le f(x)< \infty\)
\(f'(x)= 1\) for \(x > 0\), and \(f'(x)= 0\) for \(x < 0\).
ReLu es menos costosa computacionalmente que Tanh y sigmoide porque involucra operaciones matemáticas más simples. A la vez, solamente se activan unas pocas neuronas, lo que hace que la red sea dispersa, lo que la hace eficiente y fácil de calcular. En palabras simples, ReLu permite a la red aprender mucho más rápido que la funciones sigmoide y Tanh.
import numpy as np
import matplotlib.pyplot as plt
def Relu(x):
y= np.zeros(x.shape)
return np.ndarray.flatten(np.max([[y],[x]], axis =0))
x = np.linspace(-5,5,100)
plt.title('Graph of the Relu activation function')
plt.plot(x,Relu(x))
plt.grid()
plt.show()
Función de activación Softmax #
La función softmax también es un tipo de función sigmoidea, pero es útil cuando intentamos manejar problemas de clasificación.
Generalmente se usa cuando se intenta manejar múltiples clases. La función softmax comprime las salidas para cada clase a valores entre 0 y 1 al dividir cada valor por la suma de las salidas (modificadas mediante una función exponencial).
La función softmax se usa idealmente en la capa de salida del clasificador donde realmente estamos tratando de alcanzar las probabilidades para definir la categoría que corresponde de cada entrada. Formalmente la función softmax es definida como sigue-
Sea \(x=(x_1,\ldots,x_n)^t \in \mathbb{R}^n\). Softmax es una función \(S: \mathbb{R}^n \to \mathbb{R}^n\) definida por
en donde
Dado que \( S \) es una función vectorial de \( \mathbb {R} ^ n \) a \( \mathbb {R} ^ n \), la derivada es la matriz jacobiana dada por
Luego de unos simples cálculos se llega a que
en donde \(\delta_{ij}\) es llamado el delta de Kroneker definido por
El siguiente fragmento de código muestra cómo implementar \( DS \) en Python
Ejercicio#
Verifique la ecuación anterior.
# derivative (grad) of the softmax function
def softmax_grad(s):
# input s is softmax value of the original input x. Its shape is (1,n)
# i.e. s = np.array([0.3,0.7]), x = np.array([0,1])
# make the matrix whose size is n^2.
jacobian_m = np.diag(s)
for i in range(len(jacobian_m)):
for j in range(len(jacobian_m)):
if i == j:
jacobian_m[i][j] = s[i] * (1 - s[i])
else:
jacobian_m[i][j] = -s[i] * s[j]
return jacobian_m
# testing the function
import numpy as np
import scipy.special
x = np.array([1, 2])
scipy.special.softmax(x)
softmax_grad(scipy.special.softmax(x))
array([[ 0.19661193, -0.19661193],
[-0.19661193, 0.19661193]])
Seleccionando una función de activación#
La regla básica de combate es que si realmente no sabe qué función de activación usar, simplemente use RELU, ya que es una función de activación general y se usa en la mayoría de los casos en estos días.
Si su salida es para clasificación binaria, la función sigmoidea es una elección muy natural para la capa de salida.
Estado del arte. Variaciones de la función de activación de ReLu#
En una red neuronal, la función de activación es responsable de transformar la entrada ponderada sumada del nodo en la activación del nodo o salida para esa entrada.
La función de activación ReLU es una función lineal por partes que tiene como salida a la entrada directamente si es positiva; de lo contrario, dará salida a cero. Se ha convertido en la función de activación predeterminada para muchos tipos de redes neuronales porque un modelo que la usa es más fácil de entrenar y, a menudo, logra un mejor rendimiento.En una red neuronal, la función de activación es responsable de transformar la entrada de pesos desde el nodo en la activación de la salida del nodo para dicha entrada.
Limitaciones de las funciones de activación sigmoide y Tanh#
Se prefieren las funciones de activación no lineales, ya que permiten que los nodos aprendan estructuras más complejas en los datos. Tradicionalmente, dos funciones de activación no lineales ampliamente utilizadas son las funciones de activación tangente sigmoidea e hiperbólica.
Un problema general con las funciones sigmoide y Tanh es que saturan en los extremos. Esto significa que los valores grandes se ajustan a 1 y los valores pequeños a -1 (Tanh) o 0 (sigmoide) respectivamente. Además, las funciones solo son realmente sensibles a los cambios alrededor del punto medio de su entrada, como 0.5 para sigmoide y 0.0 para Tanh.
La sensibilidad y saturación limitadas de la función ocurren independientemente de si la activación sumada del nodo proporcionado como entrada contiene información útil o no. Una vez saturado, se vuelve un desafío para el algoritmo de aprendizaje seguir adaptando los pesos para mejorar el rendimiento del modelo.
\( \to\) Las unidades sigmoidales se saturan en la mayor parte de su dominio: se saturan a un valor alto cuando \( z \) es muy positivo, se saturan a un valor bajo cuando \( z \) es muy negativo y solo son muy sensibles a su entrada cuando z está cerca de 0.
Finalmente, a medida que la capacidad del hardware aumentó con el uso de las GPU, las redes neuronales muy profundas que utilizan funciones de activación sigmoidea y tanh, no se pueden entrenar fácilmente.
Las capas profundas en redes grandes que utilizan estas funciones de activación no lineales no reciben información de gradiente útil. El error que se propaga a través de la red y que se usa para actualizar los peso hace que el gradiente de la red sufra de unp de dos problemas.
Tiende a ser cero (el gradiente se desvanece).
Tiende a ser infinito (el gradiente explota).
Los gradientes que desvanencen o que explotan hacen que sea difícil saber en qué dirección deben moverse los parámetros para mejorar la función de pérdida.
Evitando que los gradientes desaparezcan mediante el uso de la función de activación ReLU#
Para utilizar el descenso de gradiente estocástico con retropropagación de errores para entrenar redes neuronales profundas, se necesita una función de activación que se vea y actúe como una función lineal, pero que sea, de hecho, una función no lineal que permita aprender relaciones complejas en los datos.
La función también debe proporcionar más sensibilidad a la entrada de suma de activación y evitar una fácil saturación.
La solución había estado dando vueltas en el campo durante algún tiempo, aunque no se destacó hasta que algunos artículos de 2009 y 2011 arrojaron luz sobre ella.
La solución es utilizar la función de activación lineal rectificada, o ReLU para abreviar.
Un nodo o unidad que implementa esta función de activación se conoce como unidad de activación lineal rectificada, o ReLU. A menudo, las redes que utilizan la función rectificadora para las capas ocultas se denominan redes rectificadas.
\(\leadsto\) La adopción de ReLU puede considerarse fácilmente uno de los pocos hitos en la revolución del aprendizaje profundo, p. ej. las técnicas que ahora permiten el desarrollo rutinario de redes neuronales muy profundas.
Debido a que las unidades lineales rectificadas son casi lineales, conservan muchas de las propiedades que hacen que los modelos lineales sean fáciles de optimizar con métodos basados en gradientes. También conservan muchas de las propiedades que hacen que los modelos lineales generalicen bien.
Ventaja de la función de activación ReLU#
La función de activación lineal rectificada se ha convertido rápidamente en la función de activación predeterminada al desarrollar la mayoría de los tipos de redes neuronales.
Como tal, es importante tomarse un momento para revisar algunos de los beneficios del enfoque, destacados por primera vez por Xavier Glorot, et al. en su documento histórico de 2012 sobre el uso de ReLU titulado Deep Sparse Rectifier Neural Networks.
Simplicidad computacional. La función del rectificador es trivial de implementar y requiere una función max(). Esto es diferente a la función de activación sigmoidea y tanh que requieren el uso de un cálculo exponencial.
Escasa representación. Un beneficio importante de la función de rectificador es que es capaz de generar un valor cero verdadero. Esto es diferente a las funciones de activación tanh y sigmoidea que aprenden a aproximarse a una salida muy cercana a cero, pero no un verdadero valor cero. Esto significa que las entradas negativas pueden generar valores cero verdaderos, lo que permite la activación de capas ocultas en redes neuronales para contener uno o más valores cero verdaderos. Esto se denomina representación dispersa y es una propiedad deseable en el aprendizaje representacional, ya que puede acelerar el aprendizaje y simplificar el modelo.
Comportamiento lineal. La función rectificadora se ve y actúa principalmente como una función de activación lineal. En general, una red neuronal es más fácil de optimizar cuando su comportamiento es lineal o casi lineal.
Entrene redes profundas. Es importante destacar que el (re) descubrimiento y la adopción de la función de activación lineal rectificada significó que se hizo posible explotar las mejoras en el hardware y entrenar con éxito redes profundas de múltiples capas con una función de activación no lineal mediante retropropagación.
Extensiones y alternativas para ReLU#
El ReLU tiene algunas limitaciones. Una de las principales limitaciones de ReLU es el caso en el que las actualizaciones de gran peso pueden significar que la entrada sumada a la función de activación es siempre negativa, independientemente de la entrada a la red.
Esto significa que un nodo con este problema siempre generará un valor de activación de 0.0. Esto se conoce como un «ReLU moribundo».
Algunas extensiones populares de ReLU relajan la salida no lineal de la función para permitir pequeños valores negativos de alguna manera.
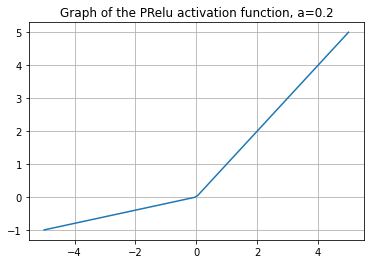
ReLU parametrizada (PReLu), 2015#
La función de activación PRelu es definida por
Aquí \( y_i \) es la entrada de la activación no lineal \( f \) en el \( i \) -ésimo canal, y \( a_i \) es un coeficiente que controla la pendiente del parte negativa. El subíndice i en ai indica que permitimos la activación no lineal para variar en diferentes canales.
Observe que
\(f(y_i) = max(0,y_i) + a_i min(0,y_i)\) 2.\( \begin{equation} f'(y_i) = \begin{cases} 1, & \text{ si } y_i > 0\\ a_i , & \text{ si } y_i \le 0 \end{cases} \end{equation} \)
import numpy as np
import matplotlib.pyplot as plt
def PRelu(a, x):
y= np.zeros(x.shape)
return np.ndarray.flatten(np.max([[y],[x]], axis =0)) + a*np.ndarray.flatten(np.min([[y],[x]], axis =0))
x = np.linspace(-5,5,100)
a = 0.2
plt.title('Graph of the PRelu activation function, a=0.2')
plt.plot(x,PRelu(a,x))
plt.grid()
plt.show()
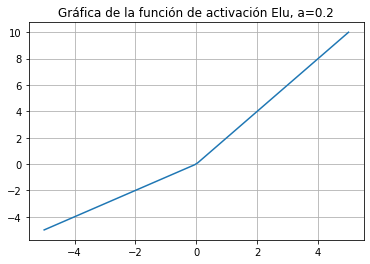
Función de activación Elu, 2016#
Elu es definida como
Observe que $\( \begin{equation} f'(x) = \begin{cases} 1, & \text{ si } x > 0\\ f(x)+\alpha, & \text{ if } x \le 0 \end{cases} \end{equation} \)$
import numpy as np
import matplotlib.pyplot as plt
def Elu(a, x):
y= np.zeros(x.shape)
return np.ndarray.flatten(np.max([[y],[x]], axis =0)) + a*np.ndarray.flatten(np.min([a*(np.exp([x]) -1),[x]], axis =0))
x = np.linspace(-5,5,100)
a = 1.0
plt.title('Gráfica de la función de activación Elu, a=0.2')
plt.plot(x,Elu(a,x))
plt.grid()
plt.show()
La siguiente tabla tomada de Wikipedia presenta las funciones de activación mas conocidas.
| Name | Plot | Function, | Derivative of , | Range | Order of continuity |
|---|---|---|---|---|---|
| Identity | 
|
||||
| Binary step | 
|
||||
| Logistic, sigmoid, or soft step | 
|
[1] | |||
| Hyperbolic tangent (tanh) | 
|
||||
| Rectified linear unit (ReLU)[9] | 
|
||||
| Gaussian Error Linear Unit (GELU)[4] | 
|
||||
| Softplus[10] | 
|
||||
| Exponential linear unit (ELU)[11] | 
|
|
|||
| Scaled exponential linear unit (SELU)[12] |
|
||||
| Leaky rectified linear unit (Leaky ReLU)[13] | 
|
||||
| Parameteric rectified linear unit (PReLU)[14] |
|
|
[2] | ||
| Sigmoid linear unit (SiLU,[4] Sigmoid shrinkage,[15] SiL,[16] or Swish-1[17]) | 
|
||||
| Mish | |||||
| Gaussian | 
|

















































![{\displaystyle (0,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e70f9c241f9faa8e9fdda2e8b238e288807d7a4)