Modelo Logístico de Clasificación con Tensorflow 2.X
Contents
Modelo Logístico de Clasificación con Tensorflow 2.X#
Introducción#
Este código fue tomado y adaptado de Google Colab. En este ejercicio usaremos el famoso conjunto de datos iris. Sin embargo no se usarán todos los datos, porque en este ejercicio vamos a introducir el modelo logístico clásico que permite separar en dos clases. Los datos de la primera clase son omitidos y los datos se recodifican para tener solamente dos clases. Próximamente usaremos todos los datos.
El modelo lineal de clasificación#
En este modelo se tienen varias variables regresoras o explicativas de entrada y una variable dicotómica de salida.
El propósito central es construir un modelo para predecir la probabilidad de que los elementos del espacio de entrada pertenezcan a una de dos clases, las cuales denotaremos como 0 y 1 respectivamente.
Supongamos que tenemos dos variables \(X_1\) y \(X_2\) que se espera permitan predecir si un elemento del conjunto de entrada pertenece a una clase: clase 1 (\(Y=1\)) o clase 0 (\(Y=0\)).
El modelo desde el punto de vista estadístico se escribe como:
en donde:
En el entrenamiento se encontrarán los pesos \(w_1,w_2,\) y el intercepto \(b\) que minimizan una determinada función de pérdida, a partir de un conjunto de datos de entrenamiento.
Una vez garantizado que la máquina generaliza bien, probando con los datos de validación, la expresión anterior se utiliza para predecir la probabilidad que un nuevo valor no observado en el espacio de entrada, digamos \((x_1,x_2)\) pertenezca a una clase.
Por construcción \(\pi\) es la probabilidad que el elemento \(x\) pertenezca a la clase \(1\). Por lo tanto si por ejemplo \(\pi = 0.8\) para un elemento, entonces lo clasificamos en la clase \(1\).
La idea central que está detrás de este tipo de modelos se puede apreciar en la siguete imagen.
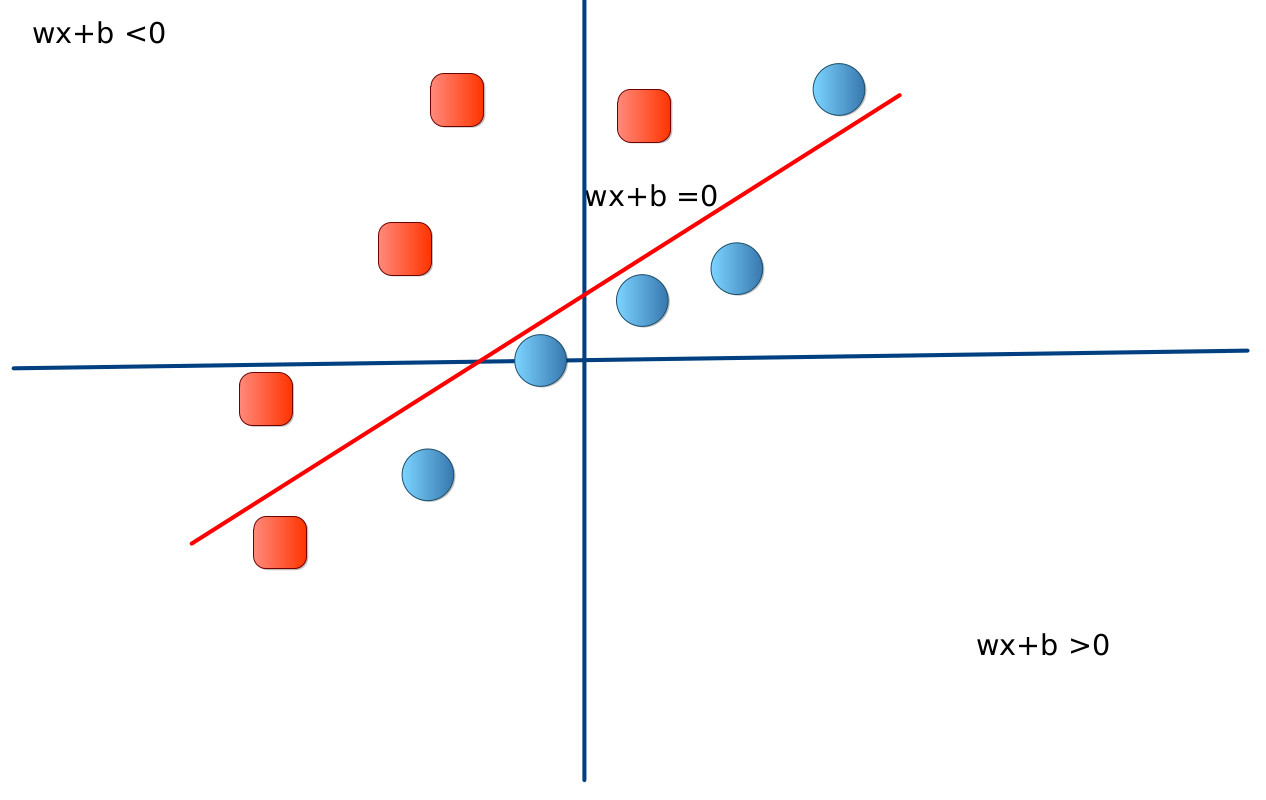
Clasificador Lineal
Se trata de un clasificador lineal simple. Vamos a suponer que la máquina de aprendizaje ya está entrenada, por lo que los parámetros \(w,b\) están fijos.
Observe que la línea roja divide el espacio \(\mathbb{R}^2\) en tres regiones. La primera es justamente la recta, que corresponde a un modelo de regresión como se estudio en la lección de regresión lineal. Sobre la línea se cumple la ecuación:
Por otro lado se tiene que si \(wx+b=0\), entonces la probabilidad \(\pi\) es dada en este caso por:
La segunda región está a la derecha. Usted puede verificar que en este caso, para todos los valores de \(x\) se tiene que \(wx+b>0\). Como consecuencia, se tiene que \(\pi>\tfrac{1}{2}\). En el caso extremo para valores \(x\) muy alejados hacia la derecha, se tiene que \(wx+b\to \infty\) y en consecuencia \(\pi\to 1\).
En la tercera región (a la izquierda) ocurre el comportamiento simétrico pero en el otro sentido. Ahora \(wx+b<0\), para todos los valores de \(x\). Se tiene que \(\pi<\tfrac{1}{2}\). En el caso extremo para valores \(x\) muy alejados hacia la izquierda, se tiene que \(wx+b\to -\infty\) y en consecuencia \(\pi\to 0\).
Conclusión#
El separador lineal funciona de la siguiente forma en este caso:
Si \(\pi(x)\) es mayor que \(0.5\), la clase que debe asignar es \(1\). Entre mayor es \(\pi(x)\) mayor tranquilidad para asignar la clase \(1\) al elemento \(x\) en el espacio de entrada.
Si \(\pi(x)\) es menor que \(0.5\), la clase que debe asignar es \(0\). Entre menor es \(\pi(x)\) mayor tranquilidad para asignar la clase \(0\) al elemento \(x\) en el espacio de entrada.
Si \(\pi(x)=0.5\), no se puede asignar una clase. Para valores muy cercanos a \(0.5\), no se debe asignar una clase directamente. Si fuera necesario tomar una decisión, lo mejor es seleccionar la clase de forma aleatoria. Como regla de combate, si \(0.48 \le \pi(x)\le 0.52\), seleccionar aleatoriamente.
Importar los módulos requeridos#
try:
%tensorflow_version 2.x
except Exception:
pass
from __future__ import absolute_import, division, print_function, unicode_literals
import pandas as pd
import seaborn as sb
import tensorflow as tf
from tensorflow import keras
from tensorflow.estimator import LinearClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score
print(tf.__version__)
2.9.1
Carga del conjunto de datos Iris#
# nombres de las columnas de los datos
col_names = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Species']
target_dimensions = ['Setosa', 'Versicolor', 'Virginica']
# lee los datos
training_data_path = tf.keras.utils.get_file("iris_training.csv", "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv")
test_data_path = tf.keras.utils.get_file("iris_test.csv", "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv")
training = pd.read_csv(training_data_path, names=col_names, header=0)
test = pd.read_csv(test_data_path, names=col_names, header=0)
test
| SepalLength | SepalWidth | PetalLength | PetalWidth | Species | |
|---|---|---|---|---|---|
| 0 | 5.9 | 3.0 | 4.2 | 1.5 | 1 |
| 1 | 6.9 | 3.1 | 5.4 | 2.1 | 2 |
| 2 | 5.1 | 3.3 | 1.7 | 0.5 | 0 |
| 3 | 6.0 | 3.4 | 4.5 | 1.6 | 1 |
| 4 | 5.5 | 2.5 | 4.0 | 1.3 | 1 |
| 5 | 6.2 | 2.9 | 4.3 | 1.3 | 1 |
| 6 | 5.5 | 4.2 | 1.4 | 0.2 | 0 |
| 7 | 6.3 | 2.8 | 5.1 | 1.5 | 2 |
| 8 | 5.6 | 3.0 | 4.1 | 1.3 | 1 |
| 9 | 6.7 | 2.5 | 5.8 | 1.8 | 2 |
| 10 | 7.1 | 3.0 | 5.9 | 2.1 | 2 |
| 11 | 4.3 | 3.0 | 1.1 | 0.1 | 0 |
| 12 | 5.6 | 2.8 | 4.9 | 2.0 | 2 |
| 13 | 5.5 | 2.3 | 4.0 | 1.3 | 1 |
| 14 | 6.0 | 2.2 | 4.0 | 1.0 | 1 |
| 15 | 5.1 | 3.5 | 1.4 | 0.2 | 0 |
| 16 | 5.7 | 2.6 | 3.5 | 1.0 | 1 |
| 17 | 4.8 | 3.4 | 1.9 | 0.2 | 0 |
| 18 | 5.1 | 3.4 | 1.5 | 0.2 | 0 |
| 19 | 5.7 | 2.5 | 5.0 | 2.0 | 2 |
| 20 | 5.4 | 3.4 | 1.7 | 0.2 | 0 |
| 21 | 5.6 | 3.0 | 4.5 | 1.5 | 1 |
| 22 | 6.3 | 2.9 | 5.6 | 1.8 | 2 |
| 23 | 6.3 | 2.5 | 4.9 | 1.5 | 1 |
| 24 | 5.8 | 2.7 | 3.9 | 1.2 | 1 |
| 25 | 6.1 | 3.0 | 4.6 | 1.4 | 1 |
| 26 | 5.2 | 4.1 | 1.5 | 0.1 | 0 |
| 27 | 6.7 | 3.1 | 4.7 | 1.5 | 1 |
| 28 | 6.7 | 3.3 | 5.7 | 2.5 | 2 |
| 29 | 6.4 | 2.9 | 4.3 | 1.3 | 1 |
# esta sección es para omitir la clase 0: "Setosa"
training = training[training['Species'] >= 1]
# recodificar los datos de entrenamiento de manera que las clases pasen de '1' y '2' a '0' y '1'
training['Species'] = training['Species'].replace([1,2], [0,1])
# esta sección es para omitir la clase 0: "Setosa"
test = test[test['Species'] >= 1]
# recodificar los datos de entrenamiento de manera que las clases pasen de '1' y '2' a '0' y '1'
test['Species'] = test['Species'].replace([1,2], [0,1])
# omite los índices de los dos dataframes para poderlos concatenar
training.reset_index(drop=True, inplace=True)
test.reset_index(drop=True, inplace=True)
# concatena los dataframes
iris_dataset = pd.concat([training, test], axis=0)
iris_dataset.reset_index(drop=True, inplace=True)
C:\Users\User\AppData\Local\Temp\ipykernel_15020\1980235443.py:9: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
test['Species'] = test['Species'].replace([1,2], [0,1])
iris_dataset
| SepalLength | SepalWidth | PetalLength | PetalWidth | Species | |
|---|---|---|---|---|---|
| 0 | 6.4 | 2.8 | 5.6 | 2.2 | 1 |
| 1 | 5.0 | 2.3 | 3.3 | 1.0 | 0 |
| 2 | 4.9 | 2.5 | 4.5 | 1.7 | 1 |
| 3 | 6.9 | 3.1 | 5.1 | 2.3 | 1 |
| 4 | 6.7 | 3.1 | 4.4 | 1.4 | 0 |
| ... | ... | ... | ... | ... | ... |
| 95 | 5.8 | 2.7 | 3.9 | 1.2 | 0 |
| 96 | 6.1 | 3.0 | 4.6 | 1.4 | 0 |
| 97 | 6.7 | 3.1 | 4.7 | 1.5 | 0 |
| 98 | 6.7 | 3.3 | 5.7 | 2.5 | 1 |
| 99 | 6.4 | 2.9 | 4.3 | 1.3 | 0 |
100 rows × 5 columns
iris_dataset.index
RangeIndex(start=0, stop=100, step=1)
Acercamiento descriptivo a los datos#
iris_dataset.describe().transpose()
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| SepalLength | 100.0 | 6.262 | 0.662834 | 4.9 | 5.800 | 6.3 | 6.700 | 7.9 |
| SepalWidth | 100.0 | 2.872 | 0.332751 | 2.0 | 2.700 | 2.9 | 3.025 | 3.8 |
| PetalLength | 100.0 | 4.906 | 0.825578 | 3.0 | 4.375 | 4.9 | 5.525 | 6.9 |
| PetalWidth | 100.0 | 1.676 | 0.424769 | 1.0 | 1.300 | 1.6 | 2.000 | 2.5 |
| Species | 100.0 | 0.500 | 0.502519 | 0.0 | 0.000 | 0.5 | 1.000 | 1.0 |
sb.pairplot(iris_dataset, diag_kind='kde')
<seaborn.axisgrid.PairGrid at 0x1f9e26ea1c0>
correlation_data = iris_dataset.corr()
correlation_data.style.background_gradient(cmap='coolwarm', axis=None)
| SepalLength | SepalWidth | PetalLength | PetalWidth | Species | |
|---|---|---|---|---|---|
| SepalLength | 1.000000 | 0.553855 | 0.828479 | 0.593709 | 0.494305 |
| SepalWidth | 0.553855 | 1.000000 | 0.519802 | 0.566203 | 0.308080 |
| PetalLength | 0.828479 | 0.519802 | 1.000000 | 0.823348 | 0.786424 |
| PetalWidth | 0.593709 | 0.566203 | 0.823348 | 1.000000 | 0.828129 |
| Species | 0.494305 | 0.308080 | 0.786424 | 0.828129 | 1.000000 |
Separa features y targets#
X_data = iris_dataset[[m for m in iris_dataset.columns if m not in ['Species']]]
Y_data = iris_dataset[['Species']]
X_data
| SepalLength | SepalWidth | PetalLength | PetalWidth | |
|---|---|---|---|---|
| 0 | 6.4 | 2.8 | 5.6 | 2.2 |
| 1 | 5.0 | 2.3 | 3.3 | 1.0 |
| 2 | 4.9 | 2.5 | 4.5 | 1.7 |
| 3 | 6.9 | 3.1 | 5.1 | 2.3 |
| 4 | 6.7 | 3.1 | 4.4 | 1.4 |
| ... | ... | ... | ... | ... |
| 95 | 5.8 | 2.7 | 3.9 | 1.2 |
| 96 | 6.1 | 3.0 | 4.6 | 1.4 |
| 97 | 6.7 | 3.1 | 4.7 | 1.5 |
| 98 | 6.7 | 3.3 | 5.7 | 2.5 |
| 99 | 6.4 | 2.9 | 4.3 | 1.3 |
100 rows × 4 columns
Divide los datos: entrenamiento y validación#
training_features, test_features, training_labels, test_labels = train_test_split(X_data, Y_data, test_size=0.2)
print('No. of rows in Training Features: ', training_features.shape[0])
print('No. of rows in Test Features: ', test_features.shape[0])
print('No. of columns in Training Features: ', training_features.shape[1])
print('No. of columns in Test Features: ', test_features.shape[1])
print('No. of rows in Training Label: ', training_labels.shape[0])
print('No. of rows in Test Label: ', test_labels.shape[0])
print('No. of columns in Training Label: ', training_labels.shape[1])
print('No. of columns in Test Label: ', test_labels.shape[1])
No. of rows in Training Features: 80
No. of rows in Test Features: 20
No. of columns in Training Features: 4
No. of columns in Test Features: 4
No. of rows in Training Label: 80
No. of rows in Test Label: 20
No. of columns in Training Label: 1
No. of columns in Test Label: 1
stats = training_features.describe()
stats = stats.transpose()
stats
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| SepalLength | 80.0 | 6.30000 | 0.665421 | 4.9 | 5.8 | 6.3 | 6.700 | 7.9 |
| SepalWidth | 80.0 | 2.89500 | 0.317386 | 2.2 | 2.7 | 2.9 | 3.100 | 3.8 |
| PetalLength | 80.0 | 4.95625 | 0.811600 | 3.0 | 4.4 | 4.9 | 5.525 | 6.9 |
| PetalWidth | 80.0 | 1.68750 | 0.411350 | 1.0 | 1.3 | 1.6 | 2.000 | 2.5 |
stats = test_features.describe()
stats = stats.transpose()
stats
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| SepalLength | 20.0 | 6.110 | 0.646366 | 4.9 | 5.775 | 6.00 | 6.425 | 7.4 |
| SepalWidth | 20.0 | 2.780 | 0.383337 | 2.0 | 2.475 | 2.85 | 3.000 | 3.4 |
| PetalLength | 20.0 | 4.705 | 0.871463 | 3.3 | 4.075 | 4.50 | 5.300 | 6.3 |
| PetalWidth | 20.0 | 1.630 | 0.483518 | 1.0 | 1.250 | 1.55 | 2.000 | 2.4 |
Normaliza los datos#
def norm(x):
stats = x.describe()
stats = stats.transpose()
return (x - stats['mean']) / stats['std']
normed_train_features = norm(training_features)
normed_test_features = norm(test_features)
Construye la tuberia (pipeline) para la alimentación de datos de Tensorflow#
def feed_input(features_dataframe, target_dataframe, num_of_epochs=10, shuffle=True, batch_size=32):
def input_feed_function():
dataset = tf.data.Dataset.from_tensor_slices((dict(features_dataframe), target_dataframe))
if shuffle:
dataset = dataset.shuffle(2000)
dataset = dataset.batch(batch_size).repeat(num_of_epochs)
return dataset
return input_feed_function
train_feed_input = feed_input(normed_train_features, training_labels)
train_feed_input_testing = feed_input(normed_train_features, training_labels, num_of_epochs=1, shuffle=False)
test_feed_input = feed_input(normed_test_features, test_labels, num_of_epochs=1, shuffle=False)
Entrenamiento del Modelo#
feature_columns_numeric = [tf.feature_column.numeric_column(m) for m in training_features.columns]
logistic_model = LinearClassifier(feature_columns=feature_columns_numeric)
INFO:tensorflow:Using default config.
WARNING:tensorflow:Using temporary folder as model directory: C:\Users\User\AppData\Local\Temp\tmpqmde3cvx
INFO:tensorflow:Using config: {'_model_dir': 'C:\\Users\\User\\AppData\\Local\\Temp\\tmpqmde3cvx', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': allow_soft_placement: true
graph_options {
rewrite_options {
meta_optimizer_iterations: ONE
}
}
, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_experimental_max_worker_delay_secs': None, '_session_creation_timeout_secs': 7200, '_checkpoint_save_graph_def': True, '_service': None, '_cluster_spec': ClusterSpec({}), '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}
feature_columns_numeric
[NumericColumn(key='SepalLength', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None),
NumericColumn(key='SepalWidth', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None),
NumericColumn(key='PetalLength', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None),
NumericColumn(key='PetalWidth', shape=(1,), default_value=None, dtype=tf.float32, normalizer_fn=None)]
logistic_model.train(train_feed_input)
WARNING:tensorflow:From C:\Users\User\AppData\Local\Programs\Python\Python39\lib\site-packages\tensorflow\python\training\training_util.py:396: Variable.initialized_value (from tensorflow.python.ops.variables) is deprecated and will be removed in a future version.
Instructions for updating:
Use Variable.read_value. Variables in 2.X are initialized automatically both in eager and graph (inside tf.defun) contexts.
INFO:tensorflow:Calling model_fn.
WARNING:tensorflow:From C:\Users\User\AppData\Local\Programs\Python\Python39\lib\site-packages\keras\optimizers\optimizer_v2\ftrl.py:153: calling Constant.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.
Instructions for updating:
Call initializer instance with the dtype argument instead of passing it to the constructor
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Create CheckpointSaverHook.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Calling checkpoint listeners before saving checkpoint 0...
INFO:tensorflow:Saving checkpoints for 0 into C:\Users\User\AppData\Local\Temp\tmpqmde3cvx\model.ckpt.
INFO:tensorflow:C:\Users\User\AppData\Local\Temp\tmpqmde3cvx\model.ckpt-0.data-00000-of-00001
INFO:tensorflow:0
INFO:tensorflow:C:\Users\User\AppData\Local\Temp\tmpqmde3cvx\model.ckpt-0.index
INFO:tensorflow:0
INFO:tensorflow:C:\Users\User\AppData\Local\Temp\tmpqmde3cvx\model.ckpt-0.meta
INFO:tensorflow:200
INFO:tensorflow:Calling checkpoint listeners after saving checkpoint 0...
INFO:tensorflow:loss = 0.6931472, step = 0
INFO:tensorflow:Calling checkpoint listeners before saving checkpoint 30...
INFO:tensorflow:Saving checkpoints for 30 into C:\Users\User\AppData\Local\Temp\tmpqmde3cvx\model.ckpt.
INFO:tensorflow:C:\Users\User\AppData\Local\Temp\tmpqmde3cvx\model.ckpt-30.data-00000-of-00001
INFO:tensorflow:0
INFO:tensorflow:C:\Users\User\AppData\Local\Temp\tmpqmde3cvx\model.ckpt-30.index
INFO:tensorflow:0
INFO:tensorflow:C:\Users\User\AppData\Local\Temp\tmpqmde3cvx\model.ckpt-30.meta
INFO:tensorflow:200
INFO:tensorflow:Calling checkpoint listeners after saving checkpoint 30...
INFO:tensorflow:Loss for final step: 0.3873989.
<tensorflow_estimator.python.estimator.canned.linear.LinearClassifierV2 at 0x1f9e7a30ac0>
Predicciones#
train_predictions = logistic_model.predict(train_feed_input_testing)
test_predictions = logistic_model.predict(test_feed_input)
train_predictions_series = pd.Series([p['classes'][0].decode("utf-8") for p in train_predictions])
test_predictions_series = pd.Series([p['classes'][0].decode("utf-8") for p in test_predictions])
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from C:\Users\User\AppData\Local\Temp\tmpqmde3cvx\model.ckpt-30
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
INFO:tensorflow:Calling model_fn.
INFO:tensorflow:Done calling model_fn.
INFO:tensorflow:Graph was finalized.
INFO:tensorflow:Restoring parameters from C:\Users\User\AppData\Local\Temp\tmpqmde3cvx\model.ckpt-30
INFO:tensorflow:Running local_init_op.
INFO:tensorflow:Done running local_init_op.
train_predictions_df = pd.DataFrame(train_predictions_series, columns=['predictions'])
test_predictions_df = pd.DataFrame(test_predictions_series, columns=['predictions'])
training_labels.reset_index(drop=True, inplace=True)
train_predictions_df.reset_index(drop=True, inplace=True)
test_labels.reset_index(drop=True, inplace=True)
test_predictions_df.reset_index(drop=True, inplace=True)
train_labels_with_predictions_df = pd.concat([training_labels, train_predictions_df], axis=1)
test_labels_with_predictions_df = pd.concat([test_labels, test_predictions_df], axis=1)
Validación#
def calculate_binary_class_scores(y_true, y_pred):
accuracy = accuracy_score(y_true, y_pred.astype('int64'))
precision = precision_score(y_true, y_pred.astype('int64'))
recall = recall_score(y_true, y_pred.astype('int64'))
return accuracy, precision, recall
accuracy_score: En la clasificación con múltiples etiquetas, esta función calcula la precisión del subconjunto: el conjunto de etiquetas predichas para una muestra que coincide exáctamente con el conjunto de etiquetas correspondiente en
y_true.precision_score: es la razón \(\frac{tp }{tp + fp}\) en donde \(tp\) es el número de positivos verdadero y \(fp\) el número de falsos positivos. El mejor valor es \(1\) y el peor valor es \(0\).
recall_score: es la relación \(\frac{tp }{tp + fn}\) donde \(tp\) es el número de verdaderos positivos y \(fn\) el número de falsos negativos. El recuerdo es intuitivamente la capacidad del clasificador para encontrar todas las muestras positivas. El mejor valor es \(1\) y el peor valor es \(0\).
train_accuracy_score, train_precision_score, train_recall_score = calculate_binary_class_scores(training_labels, train_predictions_series)
test_accuracy_score, test_precision_score, test_recall_score = calculate_binary_class_scores(test_labels, test_predictions_series)
print('Training Data Accuracy (%) = ', round(train_accuracy_score*100,2))
print('Training Data Precision (%) = ', round(train_precision_score*100,2))
print('Training Data Recall (%) = ', round(train_recall_score*100,2))
print('-'*50)
print('Test Data Accuracy (%) = ', round(test_accuracy_score*100,2))
print('Test Data Precision (%) = ', round(test_precision_score*100,2))
print('Test Data Recall (%) = ', round(test_recall_score*100,2))
Training Data Accuracy (%) = 93.75
Training Data Precision (%) = 95.0
Training Data Recall (%) = 92.68
--------------------------------------------------
Test Data Accuracy (%) = 100.0
Test Data Precision (%) = 100.0
Test Data Recall (%) = 100.0
train_predictions_series
0 0
1 1
2 1
3 0
4 1
..
75 1
76 1
77 1
78 1
79 1
Length: 80, dtype: object
train_predictions_df
| predictions | |
|---|---|
| 0 | 0 |
| 1 | 1 |
| 2 | 1 |
| 3 | 0 |
| 4 | 1 |
| ... | ... |
| 75 | 1 |
| 76 | 1 |
| 77 | 1 |
| 78 | 1 |
| 79 | 1 |
80 rows × 1 columns