Probabilidad Conjunta y Entropía Cruzada
Contents
Probabilidad Conjunta y Entropía Cruzada#
Introducción#
En esta lección se introduce el concepto de función de probabilidad conjunta. Además se introducen los conceptos de correlación, información mutua y entropía cruzada.
El ejemplo de la moneda cargada#
Usaremos el ejemplo de la Variable Bernoulli de la lección de Variables Aleatorias. En realidad el ejemplo puede reescribirse usando como experimento el lanzamiento de una moneda cargada. Suponemos dos posibles resultados cara \((g=1)\) y sello \((g=0)\). Suponemos además que \(\text{Prob}[g=1]= 0.6\) y por tanto \(\text{Prob}[g=0]= 0.4\). El experimento consiste en lanzar tres veces la moneda cargada y anotar el resultado: cara (1) o sello (0).
Ahora definimos dos variables aleatorias. La primera que llamaremos \(X\), corresponde a contar el número de caras que salen. De acuerdo con los resultados de la lección de Variables Aleatorias, la función de probabilidad de \(X\), denotada \(p_X\) es dada por extensión de la siguiente forma:
Valor |
Experimentos |
probabilidad cada experimento |
probabilidad para este valor de \(X\) |
total |
|---|---|---|---|---|
0 |
000 |
\(0.4\times 0.4 \times 0.4\) |
0.064 |
0.064 |
1 |
100 |
\(0.6\times 0.4 \times 0.4\) |
0.096 |
|
1 |
010 |
\(0.4 \times 0.6\times 0.4\) |
0.096 |
|
1 |
001 |
\(0.4 \times 0.4\times 0.6\) |
0.096 |
0.288 |
2 |
110 |
\(0.6\times 0.6 \times 0.4\) |
0.144 |
|
2 |
011 |
\(0.4 \times 0.6\times 0.6\) |
0.144 |
|
2 |
101 |
\(0.6 \times 0.4 \times 0.6\) |
0.144 |
0.432 |
3 |
111 |
\(0.6 \times 0.6\times 0.6\) |
0.216 |
0.216 |
Recuerde que obtuvimos que \(\mathbb{E}[X]=1.8\). Además se tiene que \(\text{Var}[X]=0.72\) y \(\sigma_X = 0.849\)
Ejercicio#
Por favor verifique que si \(X\sim \text{Binom}(N,\pi)\), entonces:
\(\mathbb{E}[X]=N\pi\)
\(\text{Var}[X]=N\pi(1-\pi)\).
La segunda variable que llamaremos \(Y\) se define como sigue:
La función de probabilidad de \(Y\) , denotada \(p_Y\) es dada por extensión de la siguiente forma:
Valor |
Experimentos |
probabilidad cada experimento |
probabilidad para este valor de \(Y\) |
total |
|---|---|---|---|---|
0 |
000 |
\(0.4\times 0.4 \times 0.4\) |
0.064 |
0.064 |
1 |
100 |
\(0.6\times 0.4 \times 0.4\) |
0.096 |
|
1 |
010 |
\(0.4 \times 0.6\times 0.4\) |
0.096 |
|
1 |
001 |
\(0.4 \times 0.4\times 0.6\) |
0.096 |
|
1 |
110 |
\(0.6\times 0.6 \times 0.4\) |
0.144 |
|
1 |
011 |
\(0.4 \times 0.6\times 0.6\) |
0.144 |
|
1 |
101 |
\(0.6 \times 0.4 \times 0.6\) |
0.144 |
0.720 |
-1 |
111 |
\(0.6 \times 0.6\times 0.6\) |
0.216 |
0.216 |
Recuerde que :
Función de probabilidad conjunta#
Abordemos el problema de determinar como está relacionadas (asociadas) estas dos variables. Para empezar observe la siguiente tabla que muestra como coocurren los valores de las dos variables aleatorias:
X/Y |
0 |
1 |
-1 |
|---|---|---|---|
0 |
000 |
——— |
— |
1 |
— |
100 010 001 |
— |
2 |
— |
101 110 011 |
— |
3 |
— |
——— |
111 |
La celdas vacias indican parejas de valores \((x,y)\) que no pueden ocurrir. La función de probabilidad conjunta de la variables \(X\) y \(Y\) se define como la función de dos variables dada por:
En nuestro ejemplo, la función de probabilidad conjunta es definida por extensión de la siguiente forma
X/Y |
0 |
1 |
-1 |
\(P_X\) |
|---|---|---|---|---|
0 |
0.064 |
0.000 |
0.000 |
0.064 |
1 |
0.000 |
0.288 |
0.000 |
0.288 |
2 |
0.000 |
0.432 |
0.000 |
0.432 |
3 |
0.000 |
0.000 |
0.216 |
0.216 |
\(P_Y\) |
0.064 |
0.720 |
0.216 |
1.000 |
Distribución marginal#
Observe que en la última fila de la tabla se recupera la función de probabilidad de \(Y\). De la misma forma, en la última columna se recupera la función de probabilidad de \(X\). En este contexto de funciones de probabilidad conjunta, las funciones \(P_X\) y \(P_Y\) se llaman funciones de probabilidad marginales. En este caso, cada valor corresponde a la suma de la fila o columna correspondiente. La celda inferior derecha muestra la suma total de probabilidades, que claro debe ser 1.0.
Correlación#
El concepto de correlación está completamente asociado a la funcion de distribución conjunta de dos variables aleatorias. Esencialmente, la correlación mide como covarían las dos variables aleatorias. Supongamos que \(X\) y \(Y\) son variables aleatorias definidas sobre el mismo espacio muestral como en el ejemplo anterior.
Además supongamos que la media y la desviación estándar de cada variable se denotan como \(\mu_X\), \(\sigma_X\) y \(\mu_Y\) y \(\sigma_Y\) respectivamente. Entonces se tiene que la correlación entre las dos variables aleatorias es dada por:
Ejercicio#
Vamos a calcular la correlación de las variables del ejemplo anterior. Usaremos la segunda ecuación. La igualdad puede ser verificada sin mucha dificutad.
La única cantidad que no tenemos aún es \(\mathbb{E}(XY)\), la cual puede calcularse como sigue:
En nuestro ejemplo tenemos que:
En consecuencia se tiene que:
Información mutua#
Este concepto es el análogo a la correlación, pero en este caso desde la teoría de la información de Shannon.
Para dos distribuciones (variables aleatorias \(X\) y \(Y\)) discretas conjuntamente distribuidas, la información conjunta se define por:
Observe que si las variables aleatorias son independientes, entonces \(\mathfrak{m}(X,Y)=0\), porque \(\log P_{XY} = \log P_X\log P_Y\).
Por otro lado, Si \(X=Y\), se tiene que \(\mathfrak{m}(X,X) = H(X)\), es decir, la entropía de \(X\).
La información mutua se puede calcular siempre, teniendo en cuenta el convenio \(0 \log 0 = 0\).
Recordemos la tabla de probabilidad conjunta del ejemplo:
X/Y |
0 |
1 |
-1 |
\(P_X\) |
|---|---|---|---|---|
0 |
0.064 |
0.000 |
0.000 |
0.064 |
1 |
0.000 |
0.288 |
0.000 |
0.288 |
2 |
0.000 |
0.432 |
0.000 |
0.432 |
3 |
0.000 |
0.000 |
0.216 |
0.216 |
\(P_Y\) |
0.064 |
0.720 |
0.216 |
1.000 |
Entonces en este caso tenemos que:
La información mutua siempre es positiva e indica la cantidad de información que las dos variables cargan conjuntamente, la una de la otra.
La siguiente línea ilustra el cálculo usando Numpy.
import numpy as np
(0.064)*np.log(0.064/(0.064*.064)) +(0.288)*np.log(0.288/(0.288*0.724)) \
+(0.432)*np.log(0.432/(0.432*0.72) + 0.216*np.log(0.216/(0.216*0.216)))
0.5032013743418469
Entropía cruzada#
En teoría de la información, la entropía cruzada entre dos distribuciones de probabilidad \(P\) y \(Q\) sobre el mismo espacio muestral mide el número promedio de bits (o nats) necesarios para identificar una distribución con la otra.
En la práctica, si se considera la distribución \(P\) como la distribución verdadera y a \(Q\) como una distribución aproximante, entonces la entropía cruzada se define mediante:
Interpretación
Para la interpretación, esta es una medida de que tanto difiere \(Q\) de \(P\), medido en bits o nats. Entonces entre menor es este valor, mejor es la aproximación.
Ejercicio#
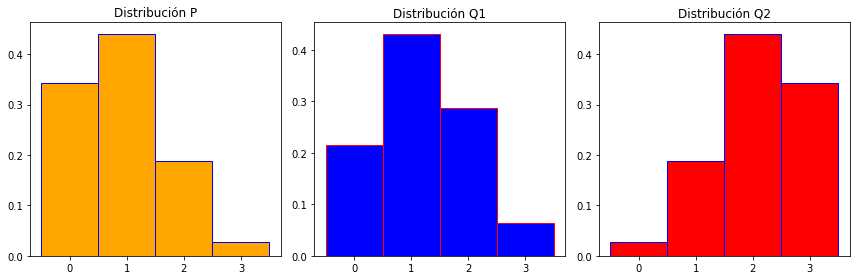
Para ilustrar el concepto, calculemos la entropía cruzada entre las distribuciones binomiales \( P=Bin(3, 0.3)\), \(Q_1=Bin(3, 0.4)\) y \(Q_2=Bin(3,0.7)\).
Vamos considerar a la distribución \(P\) como la verdadera y a \(Q_1\) y \(Q_2\) como aproximantes. Usted debe sospechar que \(Q_1\) es mejor aproximante que \(Q_2\).
Veámos.
import numpy as np
from scipy.stats import binom
import matplotlib.pyplot as plt
N, p, q1, q2 = 3, 0.3, 0.4, 0.7
P = [binom.pmf(k,N,p) for k in range(N+1)]
Q1 = [binom.pmf(k,N,q1) for k in range(N+1)]
Q2 = [binom.pmf(k,N,q2) for k in range(N+1)]
print(np.round(P,3))
print(np.round(Q1,3))
print(np.round(Q2,3))
[0.343 0.441 0.189 0.027]
[0.216 0.432 0.288 0.064]
[0.027 0.189 0.441 0.343]
H_P_Q1 = -np.sum(P*np.log(Q1))
H_P_Q2 = -np.sum(P*np.log(Q2))
print('H(P,Q1)= ', H_P_Q1 )
print('H(P,Q2)= ', H_P_Q2 )
H(P,Q1)= 1.2052697267344104
H(P,Q2)= 2.157224596768415
Finalmente un gráfico de las tres distribuciones.
fig, axes = plt.subplots(1, 3, figsize=(12, 4))
ax = axes.ravel()
label = ['0','1','2','3']
ax[0].bar(label, P, color = 'orange', edgecolor='blue',width=1)
ax[0].set_title("Distribución P")
ax[1].bar(label, Q1, color = 'blue', edgecolor='red',width=1)
ax[1].set_title("Distribución Q1")
ax[2].bar(label, Q2, color = 'red', edgecolor='blue',width=1)
ax[2].set_title("Distribución Q2")
fig.tight_layout()
plt.show()
Entropía cruzada en aprendizaje de máquinas#
Recordemos que una red neuronal de clasificación transforma un tensor de entrada en una distribución. Tal distribución indica las probabilidades de que el tensor de entrada pertenezca a cada una de las clases.
En el entrenamiento se busca encontrar los pesos sinápticos que minimizan conjuntamente la entropía cruzada entre la distribución de salida de los tensores calculada por la red neuronal y la distribución verdadera asociada a cada tensor.
Por ejemplo, supongamos que se tienen tres clases y que para un determinado tensor la clase asociada es la 1 (las posibles clases son 0,1,2).
Entonces, la distribución verdadera en este caso es \(P=(0,1,0)\). Por otro lado, supongamos que la distribución que calcula la red neuronal para este tensor es \(Q= (0.2, 0.7, 0.1)\). Entonces, la entropía cruzada para este tensor es dada por: